 |
|
|
| |
Note: The ads that you see here are not controlled, sponsored
or endorsed by Covington Innovations.
They are brought to you by Google
and will vary depending on your personal browsing history. |
| |
|
2013
July
27-31
|
What is software?
[Minor revision, 2013 August 2.]
My daughter Catherine Barrett, a law student, is working on a paper about whether software
should be protected by patents or by copyrights. In that connection, I want to explain a few
things about how software came to be, and, crucially, why I believe
software is not a written expression — it is the configuration of a machine.
Since the 1800s, there have been industrial machines that performed manufacturing operations
automatically, provided they were set up appropriately by their human operators.
Imagine, for example, a machine that accepts sheets of metal and bends, punches, and drills them
to make car doors or washing machine housings or what have you. Such things are common
in factories.
Clearly, the setup of the machine is crucial. The operator has to position a large number
of drill bits, punches, metal-forming pieces, etc., in order to get the machine to produce the
desired object.
Now imagine wanting to store the setup in some kind of machine-readable, tangible form, so
that you could just put the setup back into the machine — somehow — when you wanted
to manufacture the same thing again, rather than making all those settings manually.
That actually happened with the Jacquard loom,
an automated weaving machine that dates from, believe it or not, 1801. It weaves decorative patterns
into fabric. The patterns are controlled by sequences of punched cards — that's right, cards
with holes punched in them — so any time you want to manufacture the same pattern again, you
just feed the same cards into the machine. What's more, you can duplicate the cards to make another
Jacquard loom weave the same pattern.
Fast-forward now to the late 1800s, when machines to do arithmetic (mechanically, with gears and
dials) were fairly common. Herman Hollerith
hit upon the idea of doing arithmetic with punched cards too — that is, using cards to store
the numbers to be added up or printed out. His machines were used to process the 1890 census in
record time.
These machines were still not computers. They were
"tabulating machines" and their
behavior was controlled, not by software, but by an electromechanical setup that was
generally performed with plugboards.
By plugging wires into holes, you could, for example, tell the machine to read the first
4 digits of each card, add them to the next 4 digits, and print the result on paper.
(Tabulating machines were very popular in the 1940s and 1950s; I saw a few of them still
in use as late as the mid-1970s.)
The key idea behind computing as we know it — generally credited to
John Von Neumann — is to
store the setup in the machine the same way it stores the numbers it's working on.
That is, instead of electrically modifying the computer to control it,
you control it by storing information in it, and its circuits respond to the stored information
in order to decide what to do.
The stored instructions are called a program
and can come in from punched cards just the way numbers do.
That was the beginning of the software era.
That step made it possible for computer programs to become much more complex and sophisticated.
No longer did a program have to fit on an electrical plugboard.
Programs were information, just like the numbers or other data that the
computer was supposed to process.
In fact, crucially, a computer could treat a program as data, and do something with it
other than run it. Instead of using a plugboard to make a computer do something,
you would give it a program, on punched cards, for the computer to handle in some way.
The first programs that acted upon other programs were loaders, which grew into
operating systems. A loader simply reads a program from punched cards (or magnetic tape
or disk, or what have you), puts it into the computer's memory, and makes the computer start
reading and executing those instructions.
Loaders grew into operating systems such as Microsoft Windows, whose most
fundamental purpose is to let you store your programs in a library and run each one when
you wish.
More importantly, computers could translate programs from one "language" (or notation)
into another. The earliest punched-card computers required the cards to contain the
actual binary codes that control the CPU, essentially the equivalent of plugboard connections.
Very early, however, many people hit on the idea of writing the program in a notation that
is easy for human beings to read, punching it onto cards, and having another program
translate that notation into the actual binary code. That is why we have programming
languages such as C, C++, and Basic, and almost all computer programming has been done that
way ever since. The programs that translate C, C++, and Basic into machine code are called compilers.
It is also — I would argue — why copyright law has treated computer programs
as if they were literary works (of a rather scientific kind, like a science book).
"Writing" a program sounds seductively like writing an essay, or at least an instruction
book. In fact, however, there are important differences.
Difference number one is that copyright only protects exact expression —
words, not ideas — but we want to protect the workings of a computer program
even after the compiler translates it into machine code. When you buy Microsoft Word
at the store, you're getting a large computer program that was originally written
(as far as I know) in C++ (Microsoft doesn't actually tell us).
But what they wrote in C++ is not delivered to you. All you get is the
machine-language translation (the .exe file) together with various data files that
it requires in order to run. You do not get the program code that was written
by human beings at Microsoft. I suppose they also have a valid copyright on their
machine-language executable code, which no human being can read. (Well, I can read the
first two bytes of it, the .exe file format marker. Some people can read a little more.)
It gets worse. Courts acknowledge that to run the program, your computer must copy it.
Not only do you normally install it on your own hard disk — making a copy of what
came on the CD — but a second copying operation occurs when you click on the .exe file
(or its icon) and actually launch the program. At that time, it gets copied into RAM (working
memory) so the CPU can actually see the instructions. CPUs don't read disks; disks are far
too slow for them. Anyhow, this copying operation presumably requires permission from the
copyright owner.
What the legal profession does not seem to have realized is that when it's copied into RAM,
the program is altered in numerous ways. It's not exactly "copied." It's "relocated,"
meaning numerous instructions are altered to refer correctly to the memory locations actually
in use, not foreseeable in advance except as an overall pattern. You're not just copying the
program, you're translating it, in a sense. If it is a Microsoft .NET program, you are
actually performing the last stage of compilation too; the .exe file doesn't contain Pentium
machine instructions (except for a few at the beginning); it contains MSIL (Microsoft Intermediate
Language), which is translated into machine code by Windows when the program is loaded into RAM.
So the copyright-law situation here is complicated, and I leave that for Cathy to sort out!
It's rather like starting with an English-language book, translating (or paraphrasing) it into Spanish,
selling it to someone, and then rendering it into Portuguese page by page as they read it.
Where's the original, and how much of this does copyright cover?
Normally, I would argue, we protect the workings of machines with patents, not
copyrights, and a computer program is a specification of how something is done.
I leave this for Cathy and her learned colleagues to pursue.
One last note. Let me explain something that software is not.
You sometimes hear it said that software for computers is like audio CDs for a CD player,
or records for a phonograph, or player-piano rolls (giant punched tape) for a player piano.
It is not. The crucial difference is that an audio CD forces the player to produce
exactly a particular set of sounds (as best it can; any deficiencies that it might have are
fixed by its nature). A computer program sets up the computer to interact with
unforeseen inputs — turns the computer into a machine for processing unforeseen data
in specific ways, not just executing predetermined behaviors. It is much more like the
setup of a complex industrial machine, but it's actually even more powerful than that.
Permanent link to this entry

|
2013
July
26
|
Coming soon: Network Watcher, a handy piece of freeware
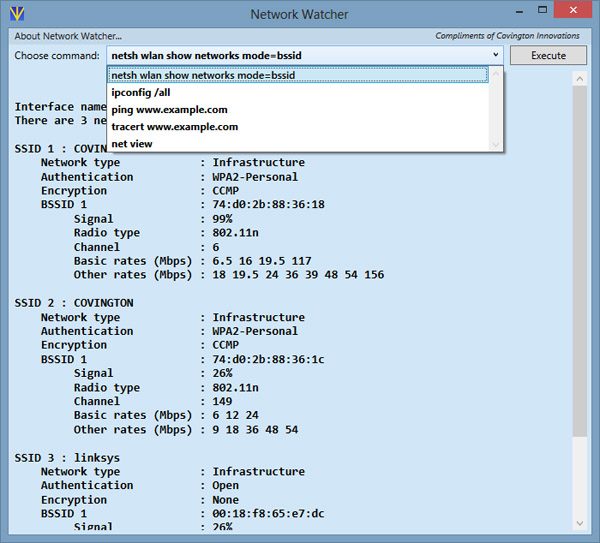
Here you see something I'm putting the finishing touches on. I'm writing it
for my own use, but I'll release it as freeware, with source code, because
it's a very interesting demonstration of how to do several unusual things
in C# (WPF).
[Note: Released September 21. Click to follow the link.]
What it does is let you pick, from a menu, any of various Windows commands that
are useful for testing a network. The command then runs with its output directed
to a window, from which it can be copied and pasted.
This saves you having to remember exactly how to type each of these
commands. That's all... but it's enough to make it handy, I think.
Permanent link to this entry
|
2013
July
25
(Extra)
|
Windows command to show all Wi-Fi networks, with attributes
Netstumbler (remember that?) doesn't work under Windows 7 and 8, but there's a
built-in command to give you the same information. Just type:
netsh wlan show networks mode=bssid
and you'll get useful information such as this:
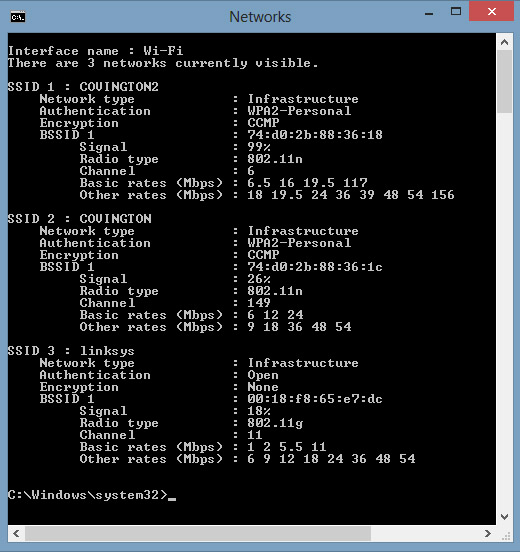
Notice that you can see the channels and signal strength.
Notice also that one of my neighbors has an unsecured wireless network —
one that I could use, and so could anybody driving by.
Don't do that, please — you're inviting eavesdroppers,
and you might get framed for someone else's criminal activity.
Want to do all of this at the click of a mouse? Just choose "New shortcut"
on the desktop, and give the location of the shortcut as:
cmd /k netsh wlan show networks mode=bssid
(the first part, "cmd /k", makes the command window stay there after the
command finishes). Handy.
Permanent link to this entry
|
2013
July
25
|
A strange Windows networking problem
Laptops wake up unable to see anything on the LAN except themselves
[Corrections, August 7 and August 15.]
NOTE: On further investigation, the problem described here (multiple conflicting
master browsers on the same LAN) was a consequence of the problem, not the cause
of it. The steps described here mitigate some of the symptoms but do not eliminate
the problem, which may be the fault of the router; we're still investigating.
To restore LAN access, it it necessary to reboot the router; power-cycling the
afflicted laptop (or even changing from Windows do Linux) does not clear up the
problem, and apparently, neither does rebooting the master browser.
One of the problems we attributed to our old router actually seems to be the fault
of something else. The symptoms were:
- On resuming from sleep mode, a laptop is unable to see anything on the network
except itself. (If you open a file folder and then navigate to Network, or if you
type the command net view, you see, at most, the laptop itself, not other
computers that are sharing files. Note that you are not supposed to see computers
that are not sharing files.)
- At least on the afflicted laptop, and perhaps elsewhere, overall network performance
is very slow, and Internet bandwidth is poor.
I don't have a complete explanation, but I have a working theory.
Our network consists of several laptops, which are often shut down or put into sleep
mode, and two desktops that act as servers and are running all the time.
Every Windows network has a master browser,
the computer chosen to tell the other computers what's on the network.
The master browser is "elected" whenever the network discovers it needs one and
doesn't have one. If it goes away, a replacement is elected immediately.
Earlier versions of Windows had a command called browstat to tell you which
machine was master browser. That has gone away, but you can use the command
nbtstat -a computername
to find out whether a particular computer is master browser; just look for MSBROWSE
in the output of the command, when you name that computer.
Well... Each of the afflicted laptops had somehow elected itself master browser
at a time (presumably while waking up from sleep) that it couldn't see the other
computers. And I hear from reliable sources that if two computers both try to be
master browser, and don't know about each other, they will flood the network with
traffic, degrading performance.
I wanted one of the desktops always to be master browser.
Accordingly, on all of the laptops, I made the registry setting MaintainServerList=No
as described here.
This seems to have worked.
But I shouldn't have had to do this. Windows networking is supposed to recover readily
from unreliable or broken connections. I'm thinking something else is wrong.
There are unconfirmed reports that some Intel Wi-Fi adapters will misidentify
themselves while waking up from sleep mode, causing the computer to think it is on
a whole new network. Also, the recent origin of the problem suggests that it came
in with a Windows update of some kind. I'm still investigating.
On a happier note,
happy anniversary, Melody!
Permanent link to this entry
|
2013
July
24
|
ALCon 2013
I took half a day out of my busy schedule and
spent the afternoon at ALCon 2013, the national convention of the
Astronomical League, a federation of astronomy clubs.
This was a joint meeting with the
Association of Lunar and Planetary Observers,
which had a strong presence.
We met in the planetarium of the Fernbank Science Center, using it
as an auditorum with slides projected on the ceiling.
Amateur astronomers are doing some impressive things, such as measuring the shape
of asteroids by timing when the asteroid passes in front of a star as seen from
various locations on earth; photographing surface detail on the satellites of Jupiter;
and generally monitoring the universe on a much more full-time basis than the
professional observatories do. In fact, NASA calls on prominent amateurs to tell
them what is happening on Jupiter at any particular time, or whether the colors in a
picture look accurate!
Permanent link to this entry
|
2013
July
23
|
Recommended: Asus RT-AC66U Dual-Band Wireless-AC1750 Gigabit Router

This week our wireless router succumbed
to router rot after just 23 months of
faithful service.
Communication gradually became slower, and I had to reboot the
router every day or two in order to maintain a fully
functioning LAN and Internet connection.
I don't know exactly what was deteriorating:
power supply regulation? A heat sink?
"Bit rot" in the flash memory containing the firmware?
And I didn't have time to perform any tests.
Meanwhile, wireless routers have come up in the world.
The have more powerful transmitters and, as often as not,
more than one of them.
That brings me to the Asus RT-AC66U.
It is solidly built, with a metal enclosure and a stand
that helps it dissipate heat.
The setup procedure is just like the Linksys E3000 that it replaced: put it on your
wired LAN, go to http://192.168.1.1, and go through the menus —
except that this one offers an easy step-by-step process for
initial setup. And it keeps its own logs, without requiring me
to add a flash drive or disk drive. It can work as a VPN and
FTP host if I choose to set it up that way.
The biggest change we've noticed is that it delivers a stronger
wireless signal. Apart from that, it does what the old router
did when it was young and vigorous.
I bought it at Best Buy, locally, and paid an extra 15% for a 2-year
on-the-spot-replacement extended warranty. The router is mission-critical
at Covington Innovations.
I'll probably try reflashing the old router to see whether that
helps it, later on, although it will be hard to tell; the deterioration
was so insidious that it could easily seem to be working normally for
minutes or hours. The old router will at least be potentially usable
as a spare. In the meantime, I'm glad I switched to Asus.
Permanent link to this entry
|
2013
July
22
|
Free Prolog textbook too
 The Prolog textbook that I co-authored with Don Nute and André Vellino
is also
out of print, and I also have permission to distribute it free
on the Web.
The Prolog textbook that I co-authored with Don Nute and André Vellino
is also
out of print, and I also have permission to distribute it free
on the Web.
In this one, there are no substantial changes to the text; it was already a second
edition, with the wrinkles already ironed out. It is based on an early version of the
ISO Prolog standard, so it's still up to date — Prolog still works the way it
did in 1997.
Click here
to get your copy (a 12-megabyte PDF).
Permanent link to this entry
|
2013
July
21
|
Free natural language processing textbook
 My 1994 natural language processing textbook is now officially
out of print, and I have permission to distribute it free
on the Web.
My 1994 natural language processing textbook is now officially
out of print, and I have permission to distribute it free
on the Web.
I've made dozens of corrections to the text, eliminating old
typographical errors.
Click here
to get your copy (a 32-megabyte PDF).
Permanent link to this entry
|
2013
July
20
|
Aristarchus

This is a fairly decent picture of the lunar crater Aristarchus,
taken under poor conditions right after the picture I posted yesterday,
with the same telescope and camera, but this time using the camera in
video mode, and capturing a much smaller field of view, magnified.
About 2500 video frames were stacked to produce a single (reasonably)
sharp image.
Aristarchus was an ancient Greek astronomer who proposed putting the sun
rather than the earth in the center of the Solar System.
In the 1500s, Polish astronomer Nicholas Copernicus took him up on it —
giving plenty of credit to Aristarchus — and made it work.
He showed that one particular kink (epicycle) in the orbits of all the
planets would go away if you did that — it was actually the reflection
of the earth's motion. But Copernicus' system was still quite awkward.
Better astronomy had to wait for Kepler and Newton.
We usually think of Copernicus as the first modern astronomer, but Zdenek
Kopal argues in Widening Horizons that he was actually the last
ancient one. All he did — arguably — was to work out Aristarchus'
proposal. He adduced no new data and introduced no new mathematics.
He didn't solve the obvious physics problem, which was that whether the
earth moves around the sun or vice versa, we know the orbit isn't a perfect
circle, so if the earth is the one that's moving, why don't we feel it
speeding up and slowing down? That had to wait for Isaac Newton.
According to Kopal, modern astronomy starts with Tycho Brahe, who gathered
positional data on a large scale, and with Galileo, a different type of
data-gatherer, and Kepler, pursuer of new mathematical approaches.
Permanent link to this entry
|
2013
July
19
|
Once in an orange moon

I hadn't taken an astrophoto in six weeks because of an unprecedented rainy spell.
(It has rained every day that I can remember during that time.)
But on the evening of the 19th, the gibbous moon was culminating low in the sky,
and no water was falling on our heads, so I got out the Celestron 5.
The moon looked positively orange because of the murky air, and only a few
stars were visible. Nonetheless, I got a picture. Single 1/160-second exposure
with Canon 60Da direct-coupled to Celestron 5 at f/10, using Live View to eliminate
shutter vibration; postprocessed with Photoshop (color adjustment, saturation
increase, and unsharp masking).
The bright crater at the left is Aristarchus, which Sir William Herschel once
mistook for an erupting volcano, it catches so much sunlight; I also took some
high-resolution video of it and hope to have a picture ready tomorrow.
Permanent link to this entry
|
2013
July
18
|
And yet another dangerous misconception
(Fourth and last in a series on Internet safety.
Scroll down to see the preceding articles.)
[Revised.]
I forgot something that should have gone into yesterday's article.
There's another dangerous misconception about the Internet:
"What I did yesterday doesn't matter today."
This manifests itself several different ways.
I've met immature computer-criminal-wannabees who seemed to imagine
that the statute of limitations on computer crimes
runs out in about 15 minutes.
If they broke into an account half an hour ago, and haven't been
punished yet, they've gotten away scot-free.
Right? Wrong, of course.
Some people don't realize that punishment for computer misuse
can come months or years later, especially if serious laws were
broken.
Others forget that what they've posted on the Internet stays
there until they remove it, and maybe even permanently.
What you put on Facebook last year
is still on Facebook. The same goes for blogs and discussion forums.
Facebook and blogs let you remove or edit your past material, but
some discussion forums don't, particularly those with older technology.
Also, any web page that is not password-protected is likely to be
preserved on archive sites.
What you said on Usenet in 1995, or in your blog in 2000,
is still retrievable. It probably won't get a lot of attention,
but it's there.
What's more, if you've posted something on the Web that violates
copyright, or is obscene or slanderous, then as far as the law is
concerned, you're still publishing it until you take it down.
At least, if it's still there for people to see, and you could have
taken it down but didn't, they'll assume you chose to leave it up.
The difference between the Web and a newspaper is that Web publication
is continuous.
Now you know.
Permanent link to this entry
|
2013
July
17
|
Dangerous misconceptions about law and responsibility on the Internet
Back when I was handling computer security incidents for the University of Georgia,
I saw people do some strange and dangerous things.
I still see people making the same mistakes.
In this third entry in a series on Internet safety, I want to point
out some dangerous misconceptions and illusions.
The overriding misconception that gets people into trouble is,
"This isn't the real world." I'm not really me, you're not
really you, people aren't really people, laws aren't really laws.
False! Or, as Bob Stearns used to say, "R-O-N-G, wrong!"
The Internet all too easily turns into a fantasy world for some people.
But it's really part of the real world. Maybe some people can't
distinguish it from a video game. But it's not a video game.
From this, we get a number of other dangerous misconceptions:
"I don't have to obey the law." (Sometimes expressed
as, "There are no laws in cyberspace.") Both of these are completely
false. I wrote a couple of days ago about how people
have to obey copyright laws on the Web no less
than anywhere else. Laws against harassment, slander, defamation,
terroristic threats, obscenity... they all apply to you.
When you log onto your computer, you haven't left Planet Earth.
You haven't even left Podunk County, or wherever you happen to be.
When you post things on a web page or blog, you have roughly the same responsibilities
as a newspaper editor. You're writing things for thousands of other people
to read. This is true even if you're a child, even if you're "noncommercial,"
even if you're a senior citizen, and even if you think only a few close friends
will ever see what you're posting.
This brings me to the next misconception, "Only a few of my closest
friends will ever see this."
(Or, "My boss will never see this — it's for everybody in the world
except my boss.")
There are three reasons not to assume this.
The first is that the technology for keeping things secret — Facebook
accounts, Blogspot passwords, and the like — isn't perfect. The second
is that you are giving everyone a written copy, which they can easily
pass along to others by just copying and pasting. And the third
is the risk that you yourself, by accident, will open things up to the
wider public. Given enough time, it seems that everybody does this.
Conflicting purposes or moments of bad judgment conspire against you.
Accordingly, I advise people never to put anything on the World Wide Web
that would be seriously damaging if the wrong people saw it. Rely on
passwords to screen who will normally see it. Don't assume that visibility
to other people is impossible.
At the same time, don't be paranoid. Kidnappers aren't going to come and
take your child just because they saw her picture somewhere. (Kidnapping of
children by strangers is very, very rare — look it up. Almost all "missing
children" are in custody disputes.) People aren't going to impersonate you just
because they know your adddress and phone number. (Do you remember telephone books?)
On the whole, anything that would be safe in a newspaper is always safe on line too.
Next misconception, closely related: "Nobody's ever going to know who I am."
Under limited circumstances, there are some things that might be good to do under
a pen name rather than with your real name. (Be careful. Always use your
real name if you need people to trust you. Good conditions for using a pen name
are fairly limited; they mostly involve literary or art projects.)
But the thing to remember is, a made-up name is not an impenetrable shield.
People who really want to know who you are will be able to find out. How?
One way is by looking at what you write, and comparing it to what you've written under
your own name, or what they know about you from other channels.
Often, that's not needed; some people enjoy blowing their own cover.
I remember this conversation
when I was doing security for UGA:
"You need to give me a new e-mail address. My ex-boyfriend got it and is harassing me."
"Didn't we do this about a month ago?"
"Yes."
"How did he get your address after we changed it?"
"I gave it to him..."
(*Sigh.* Sometimes computer security is like that.)
Finally, the last and most dangerous misconception: "People aren't people and it doesn't
matter if I hurt them."
This is a sad illusion for people to fall under, but I've encountered it many times.
Some people seem to turn into psychopaths when they're on the Internet, especially if they
think you don't know who they are. They get their kicks out of insulting other people
and spreading misinformation about them. They genuinely seem to forget that they are
talking to, and about, real human beings, not just pawns in a video game.
On a university campus, the cure is often quick and simple: Bring the insulter and the
victim together face to face, with a mediator. In the wider world, this is often hard to
arrange. But some people live in a fantasy world in which they have the "right" to harm
other people. All the rest of us can do is shun them.
Permanent link to this entry
|
2013
July
16
|
Why older adults are especially vulnerable on the Internet
If you're over 40 - or provide computer advice to someone who is - then look over
this essay. If you're over 55, take it to heart.
My experience is that mature adults are especially vulnerable to Internet scams,
viruses, malicious tricks, and malware, for three reasons.
- Older adults grew up in an era when everything well-written and neatly printed
was reliable. They are easily taken in by fake e-mail and web sites.
- Older adults tend to follow instructions without questioning them, harking back
to an era when written instructions were almost always trustworthy.
- Older adults are more likely to imagine that someone else (maybe Microsoft or their ISP)
is managing their whole computer experience and keeping them safe.
All of these reflect, of course, the vastly different world in which we lived forty
years ago. Back in the 1970s, printing and advertising were so expensive that if
something was well-produced, you could be sure that it came from a large, accountable
organization. It might not be totally reliable, but at least the source was likely
to be held accountable.
Similarly, there were few telephone or mail scams. Laws against mail fraud were
strictly enforced (and still are). Long-distance telephony cost so much that anyone
doing scams or pranks on the telephone was sure to be local, easily within reach of
the monopoly local phone company.
And all the mass media had editors and producers. Everything that you saw on your TV
or read in your newspaper was there with the consent of the TV station manager or the
newspaper editor, respectively. It still might not be reliable, but at least someone
was taking responsibility for it, to prevent large-scale harm.
That is not the world in which we live today. In particular:
- Faking an e-mail message or a web page is extremely easy. In the old days,
the only way to get Bank of America stationery was to go to a print shop, where you
would raise suspicions
if you weren't Bank of America. Nowadays, it's easy to copy the
entire content of an e-mail message or a web site, make small changes for malicious
purposes, and then send out or set up a completely authentic-looking fake.
- Communication around the world costs nothing, and it can be very hard to tell where a message
came from. You can (and I do) get malicious e-mail from China and Russia every day,
as well as lots of fraudulent e-mail that has probably never been near the places it claims to be from.
One of the biggest weaknesses of the Internet is that there is no reliable "postmark"
on data packets — no proof of where they came from. There is information about
where they claim to be from, of course, but it isn't guaranteed to be true.
- Law enforcement is 20 years behind the times. I know because I argued with
them back in the 1990s. They didn't want to get involved in what they thought was
the "computer hobby." I told them we would be doing banking from home and facing
threats from organized crime, and most of them didn't listen.
Nowadays, they've caught up to about 1994, but far too little
effort is being put into cyber security. Just as police departments as we know
them today were made necessary by the railways and the automobile, we need to invent
a new kind of police work to handle newly arising needs.
What safety advice would I give to older adults on the Internet?
Here are several quick points:
- Learn about your computer and operating system. If you don't want to have to
know what an antivirus program is, or how to read a web address, you shouldn't have
a computer. (Likewise, if don't want to learn what a stop sign or a yield sign is,
you shouldn't be driving a car.) I know this sounds heartless, but just like driving a
car, using a computer imposes some responsibilities on you to learn things.
It's not like watching TV. You don't just turn it on and watch whatever pops up.
- Use antivirus software and update it regularly. Something you got 3 years ago,
and haven't updated, will not do. Microsoft Security Essentials is good; it's free
of charge and updates itself over the Internet along with Windows updates.
Become familiar enough with your antivirus software that you will recognize how it works
and not be taken in by fake "antivirus" messages from viruses!
- If software asks permission to alter your computer, and you're not intentionally
installing anything, don't let it. This is one good reason to run Windows Vista, 7, or 8 instead
of Windows XP — the newer versions of Windows will warn you of suspicious activity.
- Don't click on anything that pops up unexpectedly on the screen. Don't click on anything
that arrives in e-mail unless you're 100% sure it's legitimate. If a "virus warning"
pops up on the screen, don't click on it; instead, go to the Start button, find your antivirus
software, and run it from there. Likewise, if you get e-mail that says "click on this file"
or "click on this web address," don't, unless you're completely sure nothing is wrong.
- Whenever you are going to a web site that you must log in to — such as a bank, or
even Facebook — go there by typing the address yourself, or picking it from your own
favorites list, not by clicking on a link that arrived in e-mail. Those links
are very often fake, and they may say one thing and go to something entirely different
(like a link that says www.bankofamerica.com but goes to www.badguys.ru). Criminals want
you to "log in" to a fake web site (that looks just like the real one) so they can get
your password.
There. Those are the basics. It's not too hard, and it's much less perilous than
driving a car!
There's more. Click here
for more about this subject.
Permanent link to this entry
|
2013
July
15
|
Yes, they know where you are -
and they have to, or the Net wouldn't work
[Corrected.]
Amid all the talk about government spying on the Internet and other media, I've noticed
that lots of people don't understand one of the most fundamental facts about the Internet.
The server on the other end has to know where you are. Otherwise, it can't send you anything.
Every time you view a web page, you are asking that web server to send you the
contents of the page, right then.
It has to know where to send it.
You're not tuning in a radio or TV signal that is already in the air.
You're making a specific request and giving your IP address so that data can be sent to you.
That IP address is a temporary or permanent unique identifier for your connection
to the Intenet, such as your cable modem or DSL line.
When I surf the Web, it is easy for any web server anywhere to find out that I am
on a Bellsouth DSL line in Athens, Georgia. With some probing, they could probably
identify the house. They can certainly tell I'm in the same place I was in yesterday.
The Internet sends data in packets, each of which is routed separately from the others.
That's how the Internet gets its great reliability.
(It was originally designed to survive nuclear attack and keep working
if half the computers in the world suddenly disappeared!)
If a better path between two computers becomes available while you're halfway
through a session, it will start being used immediately.
If the path that you're using disappears, you won't even notice because a new
path will be found for the very next data packet.
Why doesn't the Internet have anything like "Caller ID block"? Because there is
no "telephone company" connecting your computer to someone else's.
Instead, the Internet is a complex network of networks.
Each data packet is handed off from computer to computer, going through ten or
twenty sites — or more — on its way to its destination.
They all have to know how to get packets back to you.
Nowadays almost all of these sites belong to telecom companies, but in the
old days, they could be computers anywhere; I remember sending e-mail from
Georgia to Europe via the University of Tennessee.
So it makes no sense to ask for servers not to know where you are.
They wouldn't be able to send you anything if they didn't.
At best, you can ask them not to keep records longer than actually needed for
operations. But even then, it is necessary to keep some records to
forestall denial-of-service attacks
(such as when somebody rigs a computer to request a million copies of the
same web page all at once, to keep anyone else from being able to see it)
and to measure popularity of web pages.
Technically astute readers will point out that there are ways of partly
concealing an Internet connection by using other computers as intermediaries.
Yes, but this is too cumbersome to do most of the time, if you can arrange it at all,
and even then the concealment is only partial.
By now you're wondering: Is there any privacy at all? For example, is online banking safe?
The answer is, Yes, but it's not hidden. HTTPS connections (which you use talking to
your bank, and even Facebook) protect the content of the data packets by encoding it in a
way that is very hard for strangers to decode. But they don't conceal the existence of the
data connection. People could easily find out that I'm connecting to SunTrust Bank; they just
cannot see what I'm sending or receiving.
Permanent link to this entry
|
2013
July
14
(Extra)
|
Another cost-reducing medical development?
A while back I posted about
an
example of the kind of thing I'm glad to see medical researchers discover.
Here is another.
Again, I am not able to comment on whether this will actually work in regular practice —
it is only marginally connected to my research — but it's the kind of thing
that should definitely be pursued.
Researchers in Brazil
have discovered that
sodium nitroprusside
reduces acute symptoms of schizophrenia and produces a benefit lasting at least 2 weeks
from a single dose.
Nitroprusside
is normally used to treat very high blood pressure on an emergency basis.
It also counteracts the psychosis often produced by PCP (an illegal stimulant drug).
(How was that discovered? I don't know, but I can guess: people high on PCP are often
brought to emergency rooms, and some of them surely have very high blood pressure.)
That's what led the researchers to try it on acute schizophrenia. It worked.
How it works is unclear. It may affect the NMDA neurotransmitter system,
or it may simply increase oxygenation of the brain, or both.
Nitroprusside has been around for more than 100 years and is moderately
inexpensive, especially since a single dose seems to be enough for several weeks.
So this isn't something drug companies are going to make big bucks from.
Or are they? Nitroprusside can only safely be given as a single IV dose;
toxic byproducts build up if it's used frequently. Other drugs exist,
and more can be developed, that have similar effects but are safer. (Several are already
used to treat heart disease.) Researchers, start your engines!
Permanent link to this entry
|
2013
July
14
|
Book theft from typesetters?
My friend Jeff Duntemann has discovered a strange thing going on.
Expensive scholarly books are being pirated
in electronic form, as PDF files, and
the PDF files are textual, not graphical,
which means they weren't made by scanning a printed book.
That proves that the PDF files came from the people actually typesetting and producing the book.
If the book was never released to the public as PDF or as any kind of e-book,
and perhaps was not even released to its own author as PDF (many aren't),
well, then, there's a leak in the typesetting industry somewhere.
Permanent link to this entry
|
2013
July
11-13
|
Farewell to PC World
PC World magazine is reportedly
discontinuing
its print edition,
bringing to an end the era of classic computer magazines.
I have Volume 1, Number 1, of PC World on my bookshelf.
Computer magazines (Compute!, PC, PC World, Byte,
Dr. Dobb's, PC Tech Journal, PC Techniques, Visual Developer) were a big part of my life in the 1980s.
They were where computer enthusiasts got essential information.
Not only that, but I did a lot of writing for them — dozens if not hundreds
of articles.
I reviewed several versions of Turbo Pascal for PC World.
If that doesn't give me a place in computer history, I don't know what would.
How sad should we be?
Not very, in my opinion. Magazines were good, but the Internet is better.
It is much easier to get up-to-date, detailed technical information now,
and we don't have to fill our bookshelves with it, nor root around in
indexes and tables of contents.
Permanent link to this entry
|
2013
July
9-10
|
And now for something that cannot be taken seriously
The Weenie Song is one of the
silly songs that children sing at summer camp.
Click on the link to hear it.
(Overseas readers, note that it is about hot dogs or what the Germans call Wienerwurst.)
A while back, my daughter Sharon started translating it into Latin.
I finished the job. So here it is, translated by Sharon and Michael Covington...
CARMEN DE FARCIMINARIO
Farciminarius
Atque tabernarius
Vendet canes calidos
Et cetera.
Eum transformabo,
Uxor eius ero,
Amo farciminarium!
There you have it. Farciminarius is a very rare, but real,
Latin word for "sausage-vendor."
To my heirs: When I'm gone and you publish my collected works,
you need not include this one.
Permanent link to this entry
|
2013
July
8
|
It's wrong (and illegal) to copy pictures or text from web pages
Here's something everybody needs to know.
It's wrong, and illegal, to copy pictures or text from web pages
and reuse them or redistribute them as if they were your own.
This applies to you even if you're a hobbyist,
even if you're "noncommercial,"
even if you're a child,
even if you're a Fine Artist,
even if you're just a little old lady from Pasadena,
even if you're a little green creature from Mars.
Other people's work is not yours to take.
What's so hard about that to understand?
There are really two issues here: using work without permission
and using work without giving credit to the people who produced it.
A decent person shouldn't do either one. An honest person at least
shouldn't do the second one.
And a third issue: privacy, along with libel and slander.
When you take someone else's private communications
(including pictures shared only with a group of friends) and go
public with them, you run the risk of invading the person's
privacy and damaging the person's
reputation. Newspaper reporters know at least a little about
the applicable laws. Amateur bloggers may not.
A student near me is suing
her high school for copying and reusing a picture of her in a swimsuit —
which they used as an example of what you should not put on Facebook.
The thing is, when they saw it on Facebook, it wasn't theirs to take. Facebook is copyrighted
and has an acceptable-use agreement. The lawsuit, however, revolves around her
right to privacy and the republication of a picture of her that she had shared with only
a limited group of people.
[Addendum:]
A little more about that case: The picture (which I've seen) shows the girl in a swimsuit, at an amusement park
of some kind. It is not an incriminating picture; she's not doing anything illegal or immoral,
and the picture is not indecent. It's exactly the kind of picture a girl would share with friends but not
with the public. The actual publication of the picture isn't damaging because the picture doesn't show
anything to be ashamed of. As far as I can determine,
the problem is that the school system held her up to public criticism,
republishing the picture against her express wishes and using her name as an example of
someone who did something indiscreet
on Facebook.
Now, I agree that any picture posted on Facebook is likely to circulate more widely than
the owner intends.
But it seems to me that in this case the "blame the victim" mentality
went so far that the school system actually
committed a wrongdoing in order to have a victim to blame.
That's not how it should be done!
It's no more right than burglarizing my house in order to show me that my lock isn't secure.
And it's a terrible breach of educators' ethical responsibilities.
One of my own pictures has been
stolen and reused widely — even in "original works of art" by other people —
even though it has a copyright notice and is extremely easy
to recognize.
Yes, lawsuits are possible. You have been warned.
Some people may be vague on the difference between linking to a page
(using the address to give people a way to click and go to it) and copying
material from the page. They are very different things. Bottom line:
Will the reader think the work is yours rather than mine? If so, you're doing wrong.
Permanent link to this entry
|
2013
July
7
|
Decline and fall of a shopping district
Back in the 1990s, the Pleasant Hill Road area in Duluth, Georgia (including Gwinnett Place Mall)
was our favorite shopping area. The four of us often made the one-hour drive there from Athens
for an evening excursion. Highlights included CompUSA, Media Play (CDs and DVDs),
Wolf/Ritz Camera (which sold high-end gear; I bought my Nikon 180/2.8 lens there),
and an excellent Borders bookstore.
Over the years, Gwinnett Place Mall practically dried up, as did the stores I named
and many others, but we kept going back for Fry's and Micro Center (electronics
and computers) and the large Barnes and Noble bookstore.
Today we found the Barnes and Noble bookstore all closed up and moved out. At least Fry's and
Micro Center are still there. There is a lot of vacant shopping-center space.
I am, however, happy to report that the Kangaroo gas station in Bethlehem, Georgia, is a
high-class establishment. I say this because it has rest-room graffiti in Latin (and nothing
else). The only graffiti I saw in the men's room consisted of the words
Sic semper tyrannis scrawled across the top of a poster about hand-washing procedures.
Permanent link to this entry
|
2013
July
6
|
Giving priority to certain computers on your network
If you have a local-area network that is heavily loaded, you may want to
give priority to some of the computers on it — for example, putting business
computers and servers ahead of computers used for entertainment.
Or you may want to set the priorities of different kinds of traffic
(e-mail high, game updates low).
This done through the QoS (quality of service) settings on your router.
Here's how they look on my Linksys E3000:
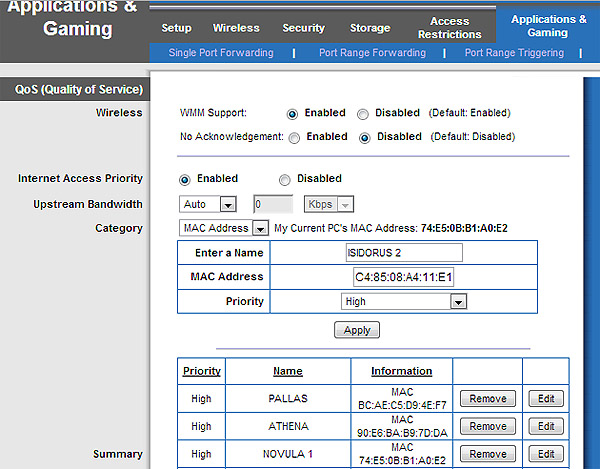
I chose to set high priority for specific computers rather than kinds of traffic.
To do this, I had to get the MAC address (physical address) of each computer.
In Windows, that is done with the command ipconfig /all at
a command prompt. Physical addresses look like 90-E6-BA-B9-7D-DA (Microsoft style)
or 90:E6:BA:B9:7D:DA (the way Linksys wants them typed). Be sure to pick the ones
that are actually used for Wi-Fi, not Bluetooth or various virtual adapters.
The router will also tell you the MAC address of the computer you are using to
connect to it at that moment — and that may be the easiest way.
I thank several Facebook friends for pointing this out to me.
Permanent link to this entry
|
2013
July
5
(Extra)
|
Headset saga continued
Further to the notes I wrote the other day,
I've successfully attached a correctly wired 2.5-mm TRRS connector
to my cheap
GE 98974 headset so that
it works with my Nokia 7020 phone, with no adapters.
And it has a problem. There's a buzzing sound from intererence. The microphone cable is
unshielded, picking up RF interference from the phone itself. And because I've
modified the headset, I can't return it. At least I got some experience doing miniature soldering.
(Hint: Lead-free SnAgCu solder was actually easier to work with than conventional solder, mainly
because of its greater mechanical strength. Also, it doesn't deteriorate when a drop of it
is left on the soldering iron for a minute or two.)
Is it engineering malpractice to use an unshielded cable with a 1000-ohm microphone?
I certainly never would have done that myself, but I figured they might have a good
reason — maybe there was a lower impedance on the other end. (And maybe there
is, with phones other than mine.)
By the way, I found out what a Nokia AD-61 adapter is.
It takes a 3.5mm TRRS connector and has a 2.5mm TRRS plug.
For unknown reasons it swaps T with the second R. This does not
match any standard pinout that I know anything about. Nokia
must have used something really strange on older phones.
Permanent link to this entry
|
2013
July
5
|
Are you broadly educated?
Highlights from a conversation on Facebook: A broad education is
not just a humanities education.
It must include science and mathematics.
I think a broadly educated person should know what all
of these things are:
- A sonnet;
- A derivative (in calculus);
- Nominative and accusative pronouns;
- A covalent bond;
- A Corinthian column;
- The invisible hand of market forces;
- An Impressionist painting;
- A statistical significance test.
If you only know the first, third, fifth, and seventh items in the list, please don't
feel that you have a license to ignore the rest.
In particular, everybody needs to get deep enough into some area of science
to understand how discoveries are made. By this I don't mean being trained to be a
"foot-soldier" or technician of science who can only implement someone else's
research program. Nor do I mean learning a lot of science "facts" as doctrines.
I mean actually knowing what discovery is like. Studying the history of science is
a good way to achieve this.
Important note: I am not claiming that everyone on earth needs this amount of
education, nor do I look down on people who have chosen to specialize more narrowly.
Narrow specialization makes us productive. I am only making a point that the
definition of a liberal education should not be weak on science. If you claim
to have a good general education, you shouldn't brag about having avoided science and
mathematics.
We also need to clue in employers that college is not trade school.
They seem to be looking for people with a bachelor's degree in Microsoft Word 2013 or
something equally narrow (and impossible). Hire the philosophy majors — they
are the smart ones!
Permanent link to this entry
Tech notes
C# note: String.CompareOrdinal is a lot faster than String.Compare. Use it
whenever the strings don't need any case or character set conversion.
Windows not updating the Desktop often enough? (Symptoms: Newly downloaded files
don't show up for a few seconds, or TortoiseSVN green checkmarks aren't up to date.)
The cure is reportedly here.
Google Chrome has a handy extension called One Window that makes all newly opened
windows turn into tabs of the main window. This is another way to make the
University of Georgia's library journals page usable.
Permanent link to this entry
|
2013
July
4
|
How densely packed are your ideas?
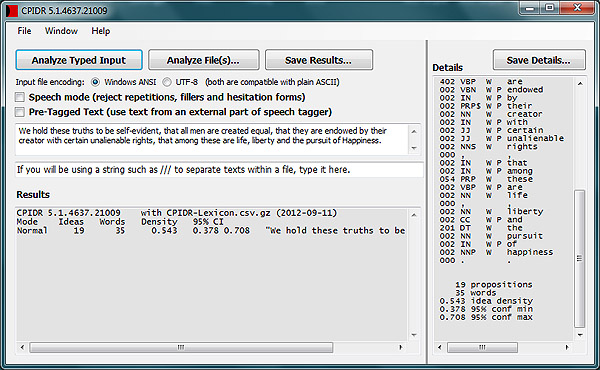
One of the software tools that will be used in the schizophrenia project
is CPIDR
(Computerized Propositional Idea Density Rater, pronounced "spider").
This is a computer program that measures propositional idea density in
written English, including transcribed speech.
What is propositional idea density? It's a measure of how many propositions
there are in the text, divided by the number of words.
A proposition is whatever can be true or false.
For example, if you say, The old gray mare has a very large nose,
there are 5 propositions: mare is old, mare is gray, mare has nose,
nose is large, largeness is "very." Spread across 9 words, this gives
an idea density of 0.55, or 55%, which is a bit on the high side for English.
I got interested in idea density after reading how Snowdon's
Nun Study used it to detect Alzheimer's Disease
50 years before the onset of symptoms. (I'm not kidding.
People whose writing had a lower idea density at age 25 were more
likely to have Alzheimer's at 75.) But Snowdon's research group
relied on training large numbers of human beings to rate the idea density
of samples of language. "We can make a computer do that," I said,
and we did.
CPIDR isn't my solo effort; a number of graduate students were involved,
especially Cati Brown, who gave it its name.
Software here;
published technical paper here.
The software has been released in two versions. CPIDR 3.2 is open-source and GPLed, freeware,
but no longer supported. CPIDR 5.1 performs much better and is free for noncommercial use
but not open-source; it requires licensing (from the University of Georgia) for commercial
applications. It is for Windows (XP, Vista, 7, 8) only.
Like all our psycholinguistics software, it is designed to be easy for nonspecialists to use.
There are probably many uses for CPIDR that haven't been thought of yet.
Besides screening for mental impairment, CPIDR can also be used to
distinguish styles of writing
in a useful way.
One last note: Higher idea density is not necessarily better. Normal for English is about 50%.
Extremely high idea density can make a text hard to read. Low idea density is more likely to occur,
and it indicates that the writer isn't bundling separate ideas together very much. This can make
for easier reading or ineffective communication, or even both.
I would like to hear from anyone interested in developing further applications of CPIDR.
Important note: CPIDR is not a ready-to-use test for Alzheimer's Disease or any other disorder.
It is a research tool.
Do not use it to "check" writing samples for "abnormality" unless you are prepared to do
large-scale statistical experimentation to find out what is abnormal.
Interestingly, in a
recent paper by Graeme Hirst and others, CPIDR was not one of the measurements that successfully
showed the effect of aging on well-known authors' style. Other measurements did show changes.
Permanent link to this entry
|
2013
July
2-3
|
Back in the saddle, helping to conquer a dread disease
Along with many other projects, I'm back in the medical research business.
Today (July 1) I started work on
this NIH-funded project
led by Dr. Michael Compton of George Washington University.
Like much of my
earlier research,
it is a study of abnormalities of language in schizophrenia.
The idea is to develop precise measurements of the
impairments caused by the disease, making it possible
to measure whether a patient is getting worse or better —
which is notoriously difficult with traditional clinical methods.
Because of Georgia's restrictions on re-employment of retired faculty
members, I'm working directly with George Washington University.
But when we get future grants, I'll be eligible to be re-employed by UGA
and will do the work there.
Permanent link to this entry
|
2013
July
1
|
A bad-engineering award to the cell phone industry
(TRRS connector follies)

I want to launch a new buzzword into the business world: Worst Practices
(the opposite of Best Practices) for things
that should not be done.
One Worst Practice is the use of the same electrical connector, for the same
purpose, on different pieces of equipment with different pinouts.
This violates the user's expectation that if the plug fits the socket,
and claims to be the right thing, it should work.
My latest peeve is that the mobile phone industry has changed standards
to introduce incompatibility for no good reason that I can see.
In the picture you see a 4-conductor phone plug, also known as a TRRS
(tip-ring-ring-sleeve) connector. You also see two rival ways
of assigning the conductors. (I caution you that these are not the
only assignments actually used!)
The good thing about both of these standards is that if you only want
to listen, not talk, you can use conventional stereo headphones with
a straight-through 3-conductor phone plug adapter, ignoring the microphone
connection (which is grounded without harm). In such a way I've been able
to listen to audio on my Nokia 7020 phone.
But the other day I wanted to use a headset (with two earphones and a microphone)
with my mobile phone. I ended up having to cut wires and resolder them to make
it work! You guessed it — the headset (from Wal-Mart) followed only the
newer standard, and the phone followed the older one.
What's more, it had 3.5-mm connectors, and I found out the hard way that
the Nokia AD-61 3.5-mm to 2.5-mm adapter is not straight-through;
it swaps a couple of conductors unexpectedly, I haven't figured out why.
I've ordered some connectors so I can continue building my own adapters.
Most distributors don't have TRRS plugs yet, but I found them
at ShowMeCables.com.
But maybe I've missed the message.
Maybe I'm supposed to get a new cell phone every year. I can't expect a "universal"
headset to fit anything more than six months old, can I? Even if it has the
same plug?
[Addendum:] A further folly to beware of: Even if you get the pinout right,
when you modify cables, you can end up with the microphone connected to an unshielded cable, making it
pick up interference from the phone itself!
Permanent link to this entry
|
|
|
This is a private web page,
not hosted or sponsored by the University of Georgia.
Copyright 2013 Michael A. Covington.
Caching by search engines is permitted.
To go to the latest entry every day, bookmark
http://www.covingtoninnovations.com/michael/blog/Default.asp
and if you get the previous month, tell your browser to refresh.
Entries are most often uploaded around 0000 UT on the date given, which is the previous
evening in the United States. When I'm busy, entries are generally shorter and are
uploaded as much as a whole day in advance.
Minor corrections are often uploaded the following day. If you see a minor error,
please look again a day later to see if it has been corrected.
In compliance with U.S. FTC guidelines,
I am glad to point out that unless explicitly
indicated, I do not receive substantial payments, free merchandise, or other remuneration
for reviewing or mentioning products on this web site.
Any remuneration valued at more than about $10 will always be mentioned here,
and in any case my writing about products and dealers is always truthful.
I have a Tektronix
TDS 210A oscilloscope on long-term loan from the manufacturer. Other reviewed
products are usually things I purchased for my own use, or occasionally items
lent to me briefly by manufacturers and described as such.
I am an Amazon Associate, and almost all of my links to Amazon.com pay me a commission
if you make a purchase. This of course does not determine which items I recommend, since
I can get a commission on anything they sell.
|
|
